Data
We collect data for statistical purposes. For example if a corporation was considering closing certain branches in the interests of cost-cutting, one thing they might do is conduct a survey over period of time to see just how regularly the branches that are under consideration are actually used.
We sometimes hear the term "foot fall" which is a way of representing how frequently a particular place may be visited and this information can be used to determine whether or not it is viable to keep the service running, or close it if it is not cost-effective.
In a case such as this we may simply count the number of visitors to the establishment on each working day, or the number of visitors in certain time periods during the day, so for example we may try to establish if a place is particularly busy towards the end of the week or if there was a particularly busy period at certain points in the working day.
Data will only become useful once it has been processed. Another name for processed data is "information".
So how do we collect data? The can of course be many ways, manually or by the use of machinery (for example, traffic counters which rely on cars running over rubber strips laid down in the road, leading to a data recorder usually chained to a nearby pole).
Once you have decided what type of survey you want to conduct, you need to identify the data you wish to collect and a suitable way of collecting it. This can be by interview, questionnaires, observation et cetera.
The "data handling cycle" will then be used to turn your data into something meaningful.
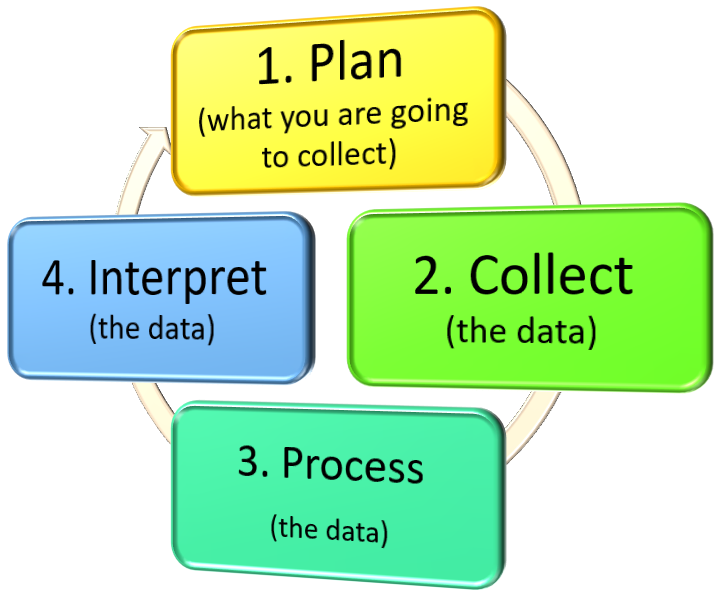
Data can be classified a number of ways:
Primary data - this is data that you would collect yourself, for example by doing a survey or some sort of experiment. For example, you might stand on a street corner and count how many of a particular model of car passes by you in a certain time. Because you have collected this data yourself, it is primary.
Secondary data - this is data that you can use in your experiments and observations, but it has not been collected by you. For example if you are comparing the numbers of centimetres of rainfall in each of the major cities, London, Birmingham, Manchester, Liverpool and Newcastle over a given period of time you would obtain your data from the Met Office, you're not likely to go and collect this data yourself. Because of this you are using secondary data.
So, now that we have a basis for data, and how to classify it:
Exercises:
Q1. A student in the top year group at a school wants to find out what other students in the year group think about the amount of homework handed out on a daily basis. What would be the data needed, and how would this be collected?
A1. The data needed could be to gauge the opinions of the students, perhaps on a multiple-choice basis, for example whether students think there is too much homework, that the amount is just right, or not enough and this could be collected either by short verbal interview or questionnaire. This would be primary data as you collect this yourself.
Q2. A sports science student want to conduct a survey to support a hypothesis that male students can throw a javelin further than female students on the sports field. What would be the data needed, and how would this be collected?
A2. The data needed in this case would be the actual distance thrown by a sample of students, * making sure that the sample is large enough to be meaningful. The student could document the findings of the survey in table form with the actual distances thrown, and whether or not the thrower was male or female in each case.This would also be primary data, as you would have collected this yourself.
* NB: You would need to make sure that the sample was large enough to be meaningful, for example choosing two male students and two female students out of the whole school would be unlikely to return a meaningful result.